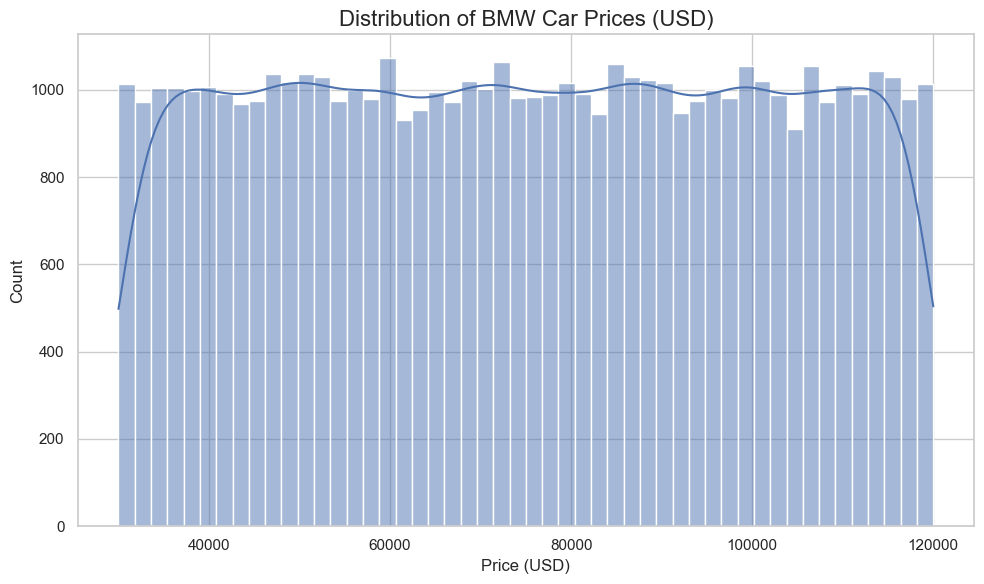
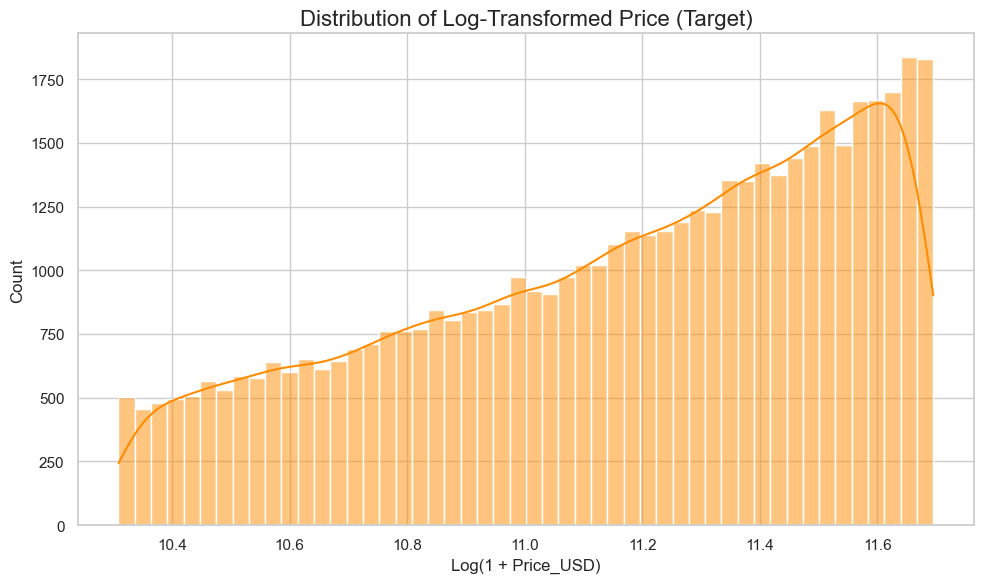
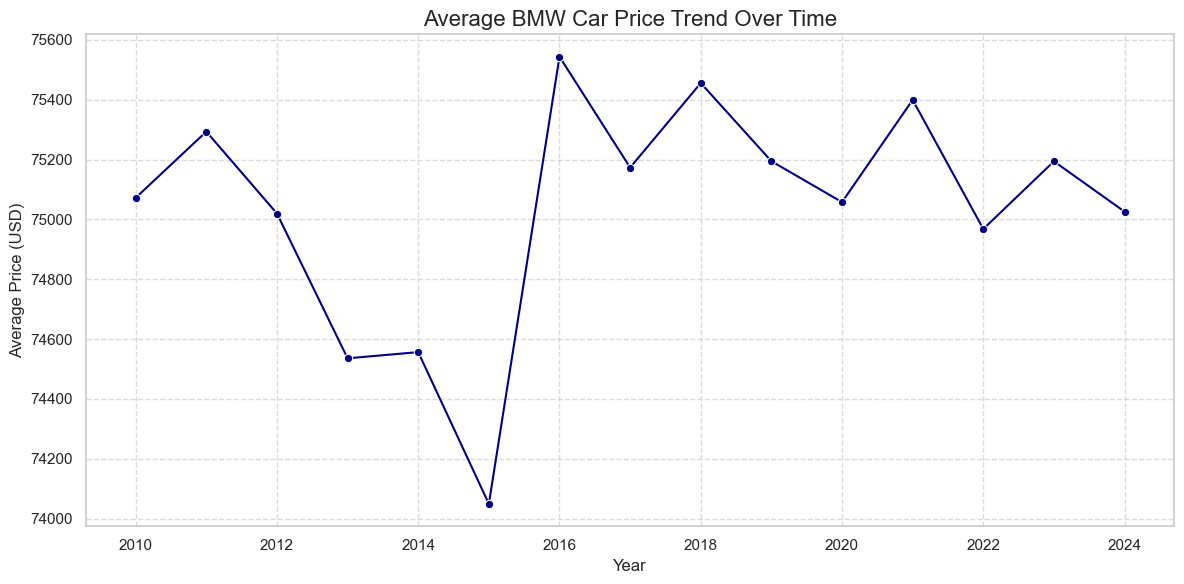
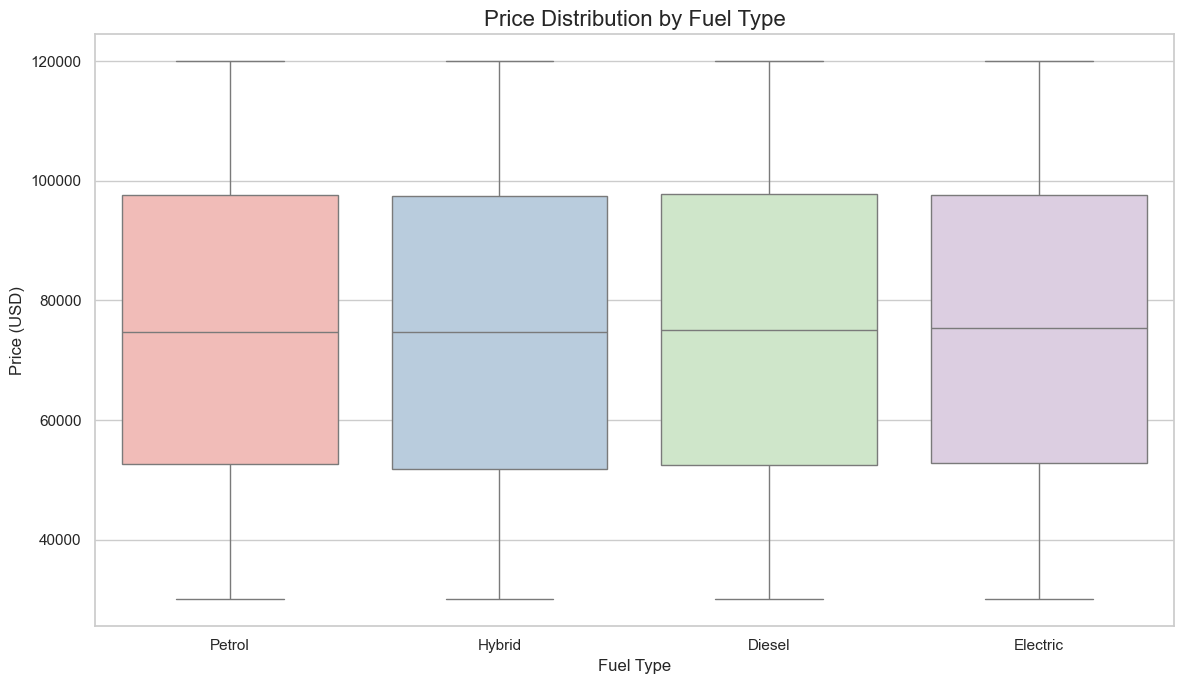
# 1. SETUP AND IMPORTS
import os
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
from pathlib import Path
from scipy import stats
warnings.filterwarnings("ignore")
pd.set_option("display.max_columns", None)
sns.set(style="whitegrid")
%matplotlib inline
# Load the Data and Set Paths
DATA_PATH = Path("..") / "data" / "bmw_worldwide_sales.csv"
OUTPUT_DIR = Path("..") / "data" / "cleaned"
VISUALS_DIR = Path("..") / "visuals"
os.makedirs(OUTPUT_DIR, exist_ok=True)
os.makedirs(VISUALS_DIR, exist_ok=True)
# Load Data
try:
df = pd.read_csv(DATA_PATH)
except FileNotFoundError:
print(f"{DATA_PATH} not found. Ensure the file is in the correct path.")
df = pd.DataFrame() # Create empty DF to prevent errors
if not df.empty:
print("Raw shape:", df.shape)
display(df.head(10))
df.info()Raw shape: (50000, 11)| Model | Year | Region | Color | Fuel_Type | Transmission | Engine_Size_L | Mileage_KM | Price_USD | Sales_Volume | Sales_Classification | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 5 Series | 2016 | Asia | Red | Petrol | Manual | 3.5 | 151748 | 98740 | 8300 | High |
| 1 | i8 | 2013 | North America | Red | Hybrid | Automatic | 1.6 | 121671 | 79219 | 3428 | Low |
| 2 | 5 Series | 2022 | North America | Blue | Petrol | Automatic | 4.5 | 10991 | 113265 | 6994 | Low |
| 3 | X3 | 2024 | Middle East | Blue | Petrol | Automatic | 1.7 | 27255 | 60971 | 4047 | Low |
| 4 | 7 Series | 2020 | South America | Black | Diesel | Manual | 2.1 | 122131 | 49898 | 3080 | Low |
| 5 | 5 Series | 2017 | Middle East | Silver | Diesel | Manual | 1.9 | 171362 | 42926 | 1232 | Low |
| 6 | i8 | 2022 | Europe | White | Diesel | Manual | 1.8 | 196741 | 55064 | 7949 | High |
| 7 | M5 | 2014 | Asia | Black | Diesel | Automatic | 1.6 | 121156 | 102778 | 632 | Low |
| 8 | X3 | 2016 | South America | White | Diesel | Automatic | 1.7 | 48073 | 116482 | 8944 | High |
| 9 | i8 | 2019 | Europe | White | Electric | Manual | 3.0 | 35700 | 96257 | 4411 | Low |
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 50000 entries, 0 to 49999
Data columns (total 11 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Model 50000 non-null object
1 Year 50000 non-null int64
2 Region 50000 non-null object
3 Color 50000 non-null object
4 Fuel_Type 50000 non-null object
5 Transmission 50000 non-null object
6 Engine_Size_L 50000 non-null float64
7 Mileage_KM 50000 non-null int64
8 Price_USD 50000 non-null int64
9 Sales_Volume 50000 non-null int64
10 Sales_Classification 50000 non-null object
dtypes: float64(1), int64(4), object(6)
memory usage: 4.2+ MB